개요
AWS 에서는 워크로드 배포와 서비스 구성뿐만이 아니라 보안 이벤트를 신속하게 감지하고 대응하기 위한 자동화를 권장한다. 자동화는 감지 및 대응 속도를 높이고 AWS 워크로드가 늘어남에 따라 보안 운영을 확장하는 데 도움이 된다. 여기서 말하는 보안 대응 자동화라는 것은 무엇일까?
보안 대응 자동화란?
특정 조건이나 이벤트를 기반으로 애플리케이션이나 리소스를 원하는 상태로 되돌리기 위해 미리 계획된 프로그램 방식의 조치를 말한다.
이러한 자동화를 구현할 때는 기존의 보안 프레임워크를 참고해야 한다.
ex ) NIST 사이버 보안 프레임워크
| Identify | AWS 환경의 리소스, 애플리케이션, 데이터를 파악함 |
| Protect | 적절한 통제 및 보안 장치를 구현함 |
| Detect | 사이버 보안 이벤트 발생을 식별하는 활동 구현 |
| Automate | 이벤트 기반으로 원하는 상태를 달성하는 계획된 프로그램 구현 |
| Investigate | 보안 이벤트의 근본 원인을 체계적으로 분석 |
| Respond | 감지된 보안 이벤트에 대해 자동 혹은 수동으로 조치 수행 |
| Recover | 보안 이벤트로 인해 손상된 기능 혹은 서비스를 복구 |
아키텍처 분석
[전체적인 흐름]
AWS 에서의 자동화 복구 흐름은 크게 3단계로 구성된다.

이 과정에서 핵심적으로 사용되는 서비스는 아래와 같다.
1. AWS CloudTrail / AWS Config : 사용자 활동 및 리소스 구성 변경 로그 수집
2. Amazon EventBridge : 이벤트 기반으로 자동화를 트리거하는 단일 서비스
3. Amazon GuardDuty : 비정상적인 활동 탐지
4. AWS Security Hub : 보안 서비스의 발견 사항들을 통합하여 상관 분석 진행
자동화 대응 예시
- VPC 보안 그룹 수정
- EC2 인스턴스 보안 패치
- 자격 증명 교체
- AWS WAF IP 차단 목록 추가
대응 자동화 설계 방법
자동화 설계 목표는 정량적이어야 한다.
- 서버에 대한 원격 관리 네트워크 접근은 제한되어야 한다.
- 서버 스토리지 볼륨은 암호화되어야 한다.
- AWS 콘솔 로그인은 MFA로 보호되어야 한다.
자동화 시나리오 : CloudTrail 비활성화 자동 복구
CloudTrail 로깅은 모든 AWS 계정과 리전에 활성화되어 있어야 한다.
만약 비활성화되면 자동으로 다시 활성화하고 보안 운영팀에게 알림을 보낸다.
Lambda 코드 핵심 로직
1. Finding 에서 TrailARN 추출
trailARN = event['detail']['findings'][0]['ProductFields']['action/awsApiCallAction/affectedResources/AWS::CloudTrail::Trail']
2. 보안팀에게 SNS 알림 발송
snspublish = snsclient.publish(
TargetArn = snsARN,
Message = "CloudTrail 로깅이 자동으로 재시작되었습니다."
)
3. CloudTrail 로깅 재활성화
client = boto3.client('cloudtrail')
enablelogging = client.start_logging(Name=trailARN)
[아키텍처]
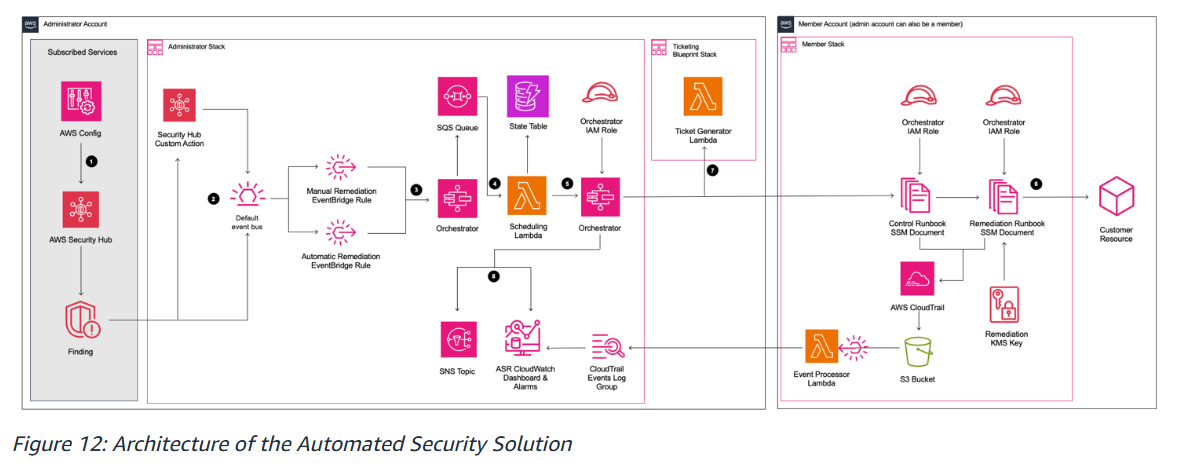
위의 아키텍처는 크게 3가지로 Administrator Account, Ticketing Blueprint Stack, MemberAccount로 구성되어있다. 이미지 속 번호 순으로 흐름을 알아보자
▷ Administrator Account
탐지 흐름
① AWS Config → AWS Security Hub → Finding 생성
AWS Conifg 가 리소스 구성 변경을 감지하고 Security Hub가 Finding을 수집한다.
② - Security Hub Custom Action : 관리자가 수동으로 Finding에 대해 트리거한다.
- Automatic Remediation EventBridge Rule : Finding 발생 시 자동으로 트리거 된다.
(두 방식 모두 Default Event Bus를 통함)
③④⑤ 오케스트레이션 흐름
Orchestrator Lambda
→ SQS Queue
→ Scheduling Lambda
→ State Table (실행 상태 관리 - DynamoDB)
→ Orchestrator (실행 조율)
⑧ 로깅 및 모니터링
CloudTrail Events Log Group
→ ASR CloudWatch Dashboard & Alarm
→ SNS Topic
▷Ticketing Blueprint Stack
⑦ Finding 발생 시 외부 티켓 시스템으로 자동 티켓 생성
(티켓 시스템 목적 : 기업의 규모가 커질수록 보안 이벤트를 놓치지 않고 누가 언제 어떻게 처리했는지 보안 담당자에게 알려줘야함)
▷MemberAccount
(이 부분에서 복구 작업이 실행된다)
⑥ 복구 실행 흐름
Orchestrator IAM Role
→ Control Runbook SSM Document (복구 전 검증)
→ Remediation Runbook SSM Document (실제 복구 실행)
→ Customer Resource
** SSM Document : 복구 로직이 담긴 스크립트
** Remediation KMS Key : 복구 작업 시 암호화 보장
보안관점 분석
한계점
1. 오탐 대응 미흡
자동화 복구 실행 → 실제로는 정상적인 배포 작업 → 서비스 장애 발생
현재 위협 탐지 후 Finding 발생 시 맥락 파악 없이 바로 실행한다.
정상 작업인지 실제 공격인지 구분하는 로직이 없다.
ex ) 개발자가 배포 중 보안 그룹을 변경한 경우 모니터링에서 공격으로 오판하여 자동으로 차단한다면 이는 서비스의 가용성에 문제를 일으킨다.
2. 멀티 계정 환경에서의 권한 복잡도
여러 계정이 생긴다면 각 계정마다 IAM Role을 부여해야하는데 Orchestrator에서 해당 Role 관리가 복잡해진다.
3. SQS 병목 가능성
SQS → Scheduling Lambda가 순차적으로 처리
이 흐름에서 대규모 공격 시 중요도가 높은 Finding이 큐에서 밀릴 수 있다.
현재 아키텍처에서는 우선순위 기반 처리 로직이 부재한다.
4. SSM Document 버전 관리 위험
Remediation Runbook이 SSM Document로 관리된다.
잘못된 버전이 배포되면 복구 로직 자체가 오작동된다.
5. 단일 리전 한계
아키텍처가 기본적으로 특정 리전 중심으로 설계된다.
멀티 리전 환경에서 Finding을 중앙으로 모으는 구성이 추가적으로 필요하다.
6. 복구 후 검증 부재
Remediation Runbook이 실행되고 난 후 실제로 복구가 잘 됐는지 확인하는 절차가 없다.
복구 실행 후 정상 상태로 돌아왔는지 검증하는 피드백 루프가 부재한다.
개선 권고 사항
1. 오탐 방지를 위해 맥락 기반 판단을 추가한다.
배포 스케줄, 변경 관리 시스템과 연동한다.
AWS Config의 변경 타임라인과 비교
아래와 같은 방식으로 오탐 방지를 할 수 있다.

2. IAM 권한 최소화 자동화
현재는 수동으로 각 Member Account IAM Role을 관리한다.
이를 AWS Organizations 와 SCP를 이용하여 중앙에서 권한 정책을 일괄 관리한다.
이후 계정을 추가할 때 자동으로 최소 권한이 적용되도록 한다.
3. Finding 우선순위 기반 처리
SQS 단일 큐로 구성된 현재 아키텍처에서 Critical , High, Low Finding으로 나눠 심각도별 별도 큐를 구성한다.
4. 멀티 리전 대응
각 리전의 Security Hub에서 집계 리전을 설정한다. (Security Hub의 Cross-Region Aggregation 기능 활용)
중앙 Administrator Account에서 통합 처리한다.
5. 복구 후 자동 검증 추가
복구한 후 Step Functions로 대기
→ AWS Config 로 현재 상태 재확인
→ 정상 → 티켓 닫음
→ 비정상 → 재시도 혹은 관리자 에스컬레이션
[참고자료]
https://aws.amazon.com/ko/blogs/security/how-get-started-security-response-automation-aws/
'AWS > 사례 분석' 카테고리의 다른 글
| AWS 인프라 분석 - Multi Account 관리 (1) | 2026.05.10 |
|---|---|
| 침해사고 분석 - Community AMI (0) | 2026.04.30 |
| 침해사고 분석 - LiveAuctioneers(2020) (0) | 2026.04.18 |
| AWS 인프라 분석 - AMI Lineage (1) | 2026.04.12 |
| 침해 사고 사례 분석 - TeamTNT (암호화폐 채굴) (0) | 2026.04.08 |



